今天看到一篇关于 Counter 是否是设计失误的文章, 引发了一些思考。 所以想深入了解一下,
Counter 用途、定义和目标。 然后再看看到底有什么问题。
什么是 Counter 类型#
Counter 是观测指标中一种非常常见的数据类型。
Counter 是一种单调递增的指标类型,
通常用于记录某个事件发生的总次数。
他的值只能增加,
不能减少,
除非发生了重置(或溢出)。
这里有一个非常关键的点:
Counter 是一个单调递增的数据类型,所以再没有发生溢出的情况下,Counter 不应该出现重置。
用途#
1. 速率类的运算#
Counter 本身的计算目标再实际生产中,
都是用来计算 QPS,OPS,EPS 的。
比如常见的 HTTP Reqest Per Second 往往是通过
rate(http_request_total[5m])
进行的计算。
这个值表示着在某一时刻的过去5分钟内平均 RPS(Request Per Second)。
不过一般情况下,为了更及时的发现问题,可能会使用
irate(...[10s])这种更细粒度的值进行展示。
2. 进程状态的监控#
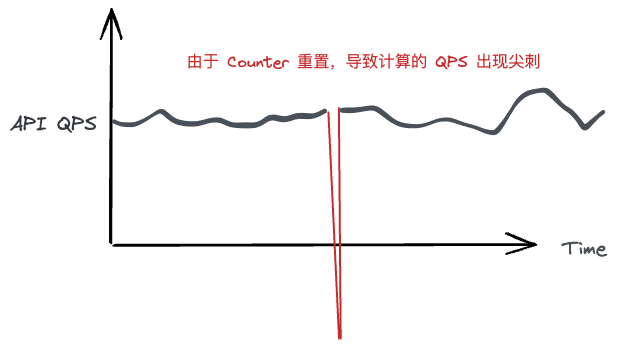
Counter 由于在进程重启后(除非有本地或其他方式的缓存), Counter 的指标会被重置。
这带来了一个问题: 一旦重置, 基于 Counter 计算指标会出现很大的抖动。
所有会有根据 Counter 做存货校验的告警规则。 比如 Counter Delta < 0 则告警。
可能会就会出现类似下图一样的监控 Panel
带来的问题#
Rate 运算的消耗#
- 在分布式结构中,Counter 无法使用 Rate 下推(IRate 可能可以),其带来的性能消耗在大规模集群下可能无法优化。
- 在降采样技术的应用上,还要区分 Rate 是发生在降采样之前还是之后的。
- 读放大
- 由于
Counter计算 Rate 的时候需要向前查询。 Counter计算 Rate 的时候,必须拥有全局的总值,再一次造成读放大。
- 由于
在我们的系统中,支撑的数据吞吐量大概是单 AZ 每秒查询135亿个点。Rate带来的性能消耗非常严重。
但是这个问题在单机领域就不是问题,不过我们的数据存储达到 PB 级别,单机无法承受。
而且确实在实践中,绝大多数的用户对于 Counter 的使用就是进行速率运算。
非连续打点导致无法预聚合#
PreAgg 预聚合是观测领域常用的降低数据规模的一种手段。
可以在一定程度上保证数据经过预聚合运算后,
数据无损。
但是对于非连续打点,
无法使用有效的周期方式配置规则,
而 Counter 通常用来计次,
当数据没有变化的时候,
那么也不会有新的数据产生。
这就导致了大多数的情况下,
Counter 往往是一个非连续的数据点。
无法预聚合在百万序列下, 性能可以说没有任何有效的优化手段。
结论#
从事实出发,
Counter 的数据类型在计算 Rate 的情况下确实不太好。
Counter 的所有使用场景都可以通过 Guage 来实现,比如
- 心跳用
up的Guage - rate、delat 统一定义为
delta的Guage,计算 rate 的时候直接除时间就好。
而客户端几乎不需要有任何计算的增加。
反而由于 Guage 类型不会溢出,
变得更加安全了。
不过仍需注意, 在偏差比较大的 Guage 的序列中, 其压缩效率可能会比较低。